By Thorsten Ulbricht (ERNI Switzerland), Michael Schroeder (ERNI Switzerland) and Christian Glück (ERNI Switzerland)
Here at ERNI, we foster interdisciplinary collaboration. This Technology Letter shows the collaboration within an interdisciplinary team. With our Experts in Agile Methodology, IoT and Machine Learning, we take a closer look at hyped buzzwords like Cloud Computing, Big Data and Artificial Intelligence. But we move beyond the hype this time to the perspective of practitioners, who share their condensed insights and perspective. Of course, we won’t forget about business and how all the activities need to be linked together so business benefits arise – to close the loop.
Driving technology changes
(Thorsten Ulbricht IoT)
Speaking with experienced developers in the middle of a Smart Building Project in 2015, I made an interesting discovery. While having a retrospective within the project to check if the team was aligned and motivated, an interesting discussion with one of the lead developers arose. Patrick, a rather introverted colleague most of the time, started to get enthusiastic. He said: “You know, I’ve been developing all sorts of software for more than 10 years. In most of these projects, I fetched data from a database, did whatever stuff with the data and pushed the modified data into a database again. From there the data was fuel for visualisation, business processes or other things. All the time, the solution was somehow decoupled from the real world and was based on either abstracted or outdated data. The insights where helpful, but they were either absolute or required a fair amount of intelligence from the user to be interpreted. Now, during the Smart Building Project, this completely changed. We built a frontend like always. And of course, there was something like a database involved. But the data came from the real world. We measured, controlled and warned with live data. We showed what was happening “now”, in a direct way that I had never experienced before. What we have created so far somehow feels alive.”
This statement from Patrick made me think as well. And as a result, I started to understand what IoT is for real. It is a Portal allowing to connect solutions into the real world.
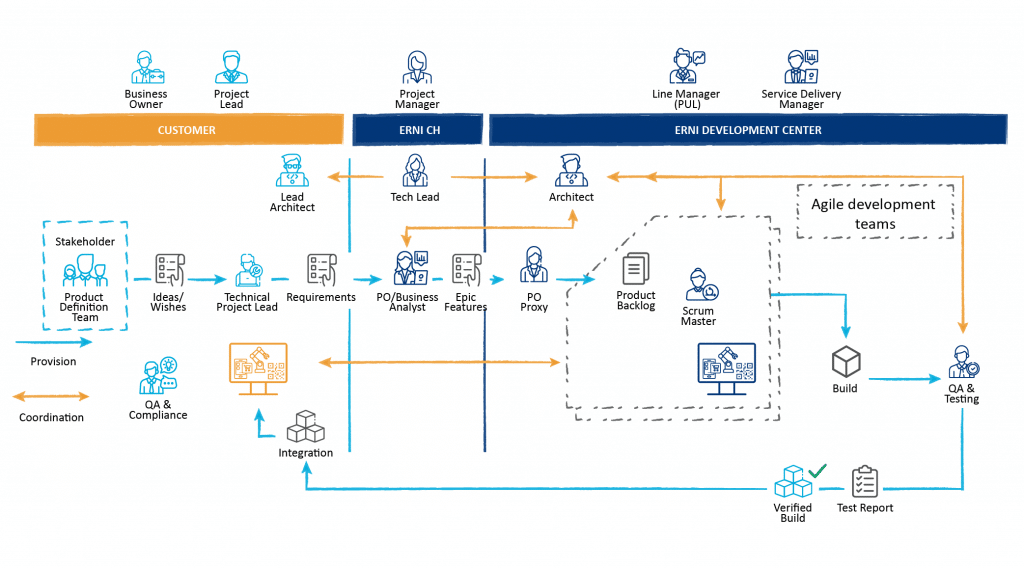
In the picture below, we can see the classical level build of a Process Automation Solution. Over time, changes in technology started from the top down. ERP and some MES systems started to be virtualised. The next step towards completely serving these functionalities with a cloud-native approach is relatively close. But the services below very often have not changed for a long time. Key drivers are security/safety concerns, lifecycle iterations of investments and sometimes the willingness for change of stakeholders.
There was one thing that brought more speed into this: Cybersecurity.
All of a sudden it turned out that a good updated system was safer than an outdated isolated one. Also, the growing number of new requirements towards the established systems were demanding new ways of thinking.
This led to a new domain in IoT. Wherever possible, these modern devices and management delivered the promise of a safe and at the same time transparent data flow. Planned on a greenfield, this has the power to massively simplify “the Pyramid”. Thinking in an architectural context, if IoT devices can directly connect to their data repository or interface, it would be possible to massively simplify architectures. Within a swim lane diagram visualising the flow of data, it would be possible to take out complete lanes without changing functionality or performance. The top layers can be directly built in a cloud, taking advantage of all high-availability features. For safety, sometimes it makes sense to keep HMI/SCADA levels on-prem. But even this could be served from the cloud. Modern low level configured devices can even make PLC devices and classical controllers obsolete. If there is a need for more complex Edge Computing, this can be done on more universal controller hardware than a plain PLC.
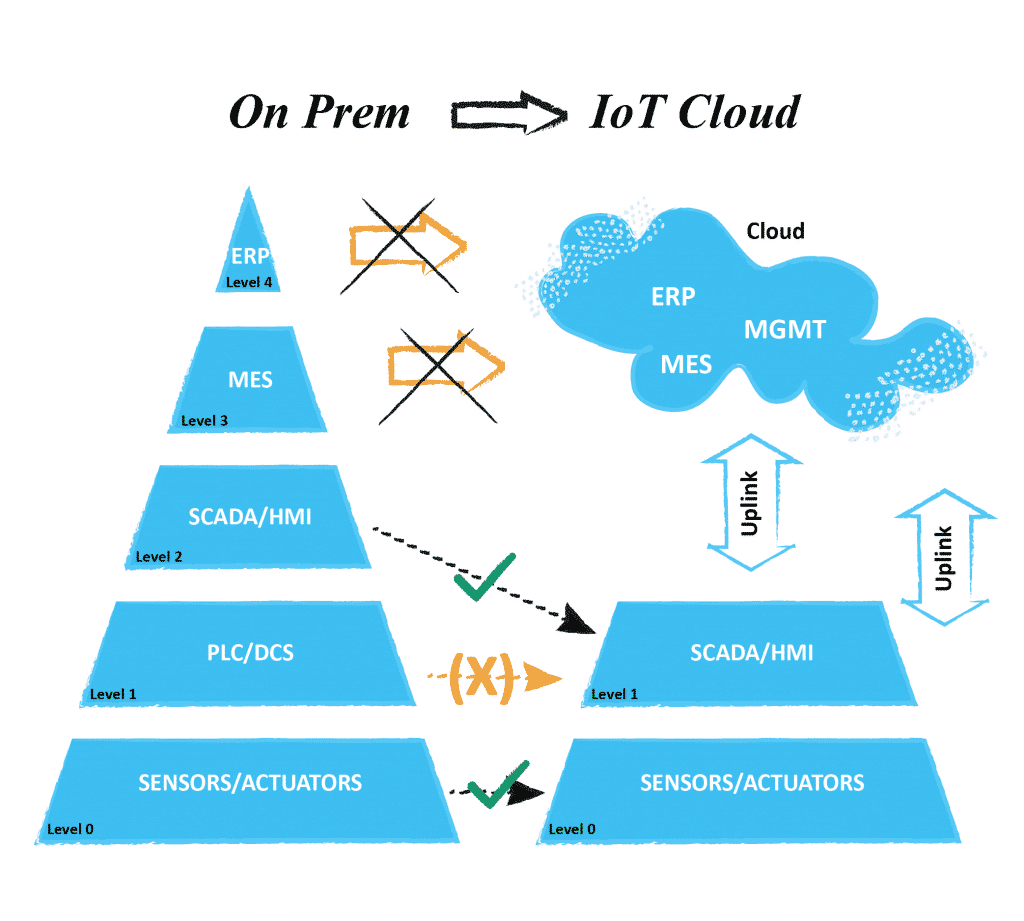
And now, everything is IoT?
Not quite. Sadly, this promise was just true for new builds on mostly greenfield projects. But what if the devices have no IoT capabilities and just “speak” proprietary protocols?
This gave rise to the idea of retrofitting existing devices.
Letting legacy devices Cloud Communicate / Retrofitting of older devices
For older legacy hardware, retrofitting can be a suitable solution. An older device can be equipped with modern IoT sensors. These sensors measure right away. No need for interfaces or digital communication. The valve opens/closes, the fan spins/stops, the temperature, humidity or vibration is good/bad; that’s it. Retrofitting is something like a digital glove around the hands you’ve been using for years. Simply said, retrofitting can build a bridge into the future. Wherever new implementations take place, IoT is often more than just a consideration.
What to do next?
After the IoT has delivered the data, where should it be stored? How should it be stored? To answer this, the right questions need to be asked first. What will the key value of the data be? How long will it need to be stored, and at what granularity? How long can operations on the data take? What is the maximum tolerated shift from processable data to reality? Very often these questions bring order and structure into architectural outcomes. But again, what’s all the hype about? To clarify this, let’s investigate the past:
In classical architecture 10 years ago, data got ingested into a database and from here a middleware layer presented and served the requested copy of the data for further processing. The closer this requested copy of the data was to the “now”, the more expensive the middleware solution was (rule of thumb).
Now with the modern and flexible cloud infrastructures in place, we can overcome that classical model. It isn’t just that the infrastructure prerequisites have dropped immensely. Once adopted, cloud technology has the power to remove complete layers of a swim lane diagram. This not only saves costs but also allows direct and simplified connection to the data sources and real slim end-to-end architectures.
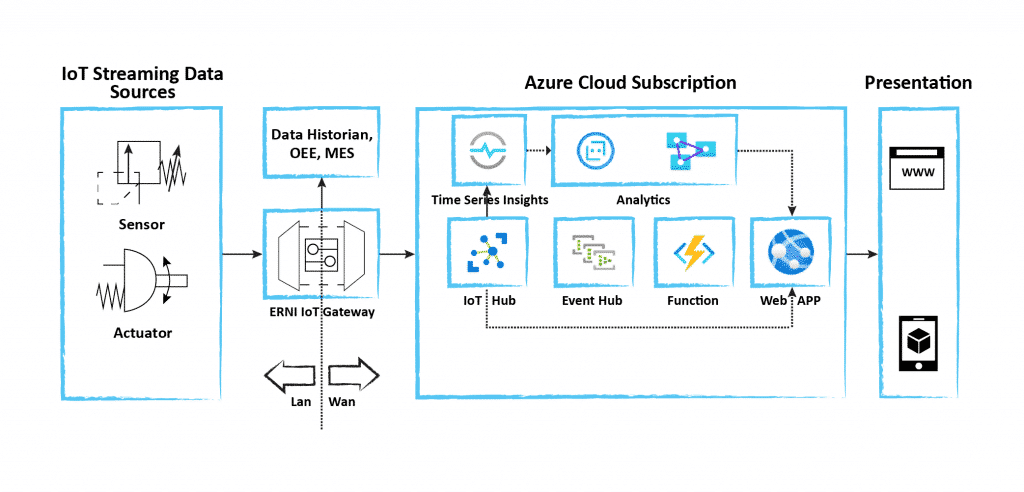
Choosing adequate services in your device-to-cloud architecture is the next step. You will need to think about what data is needed exactly in your Use Cases. In what steps will you need to perform aggregations, interpolations and the like? The graphic above shows the different ways data can go from the IoT hub if we take Azure as an example. Data can be readily interpolated within the Time Series Insights. More complex data transformations may require Azure Functions. In the end, there are numerous options on how you can reach your target. Obviously, it will be much easier to reach your Goals when you know them. The opposite is, have some data, let’s play around with it, and let do AI/ML do the magic.
Crunch the numbers in the cloud
(Michael Schroeder)
Challenges of live data (timestamping, interpolation, etc.)
IoT data brings its own challenges. On the one hand, we need know-how on how to secure (stability and security) the data transfer, and on the other hand, we need to think about how to handle the data once it enters our data lake, warehouse, data mesh, or similar architecture.
Imagine we are sourcing data from talking devices, all of the same type. Each one will send its data at slightly different time points.
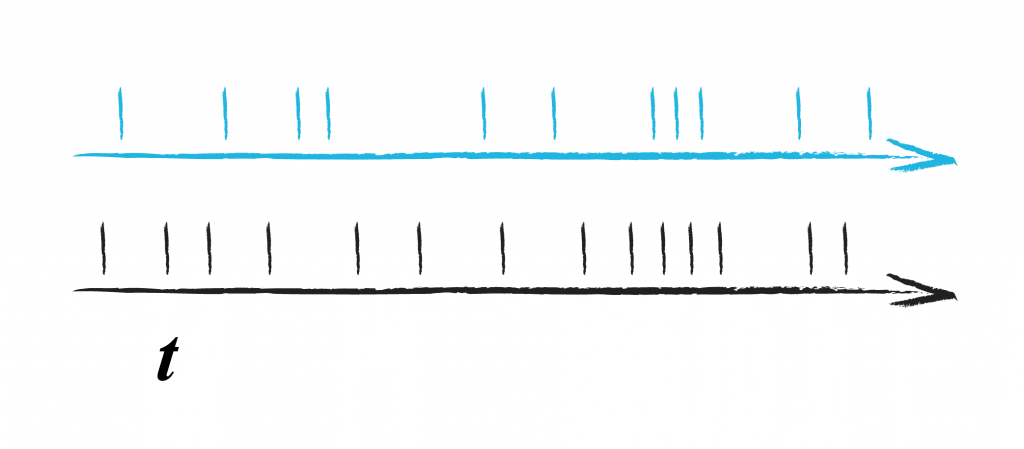
For one device, this kind of irregular event input may be ok; we can display its data and see if there is anything interesting happening. In any case, we want to eventually perform analytics including data from many devices. For this we need to align the data, which means we need to figure out what the state was at time points between the data events we receive; we need to interpolate data. For subsequent analysis and visualisation, we may want to get the data every 30 seconds in time.
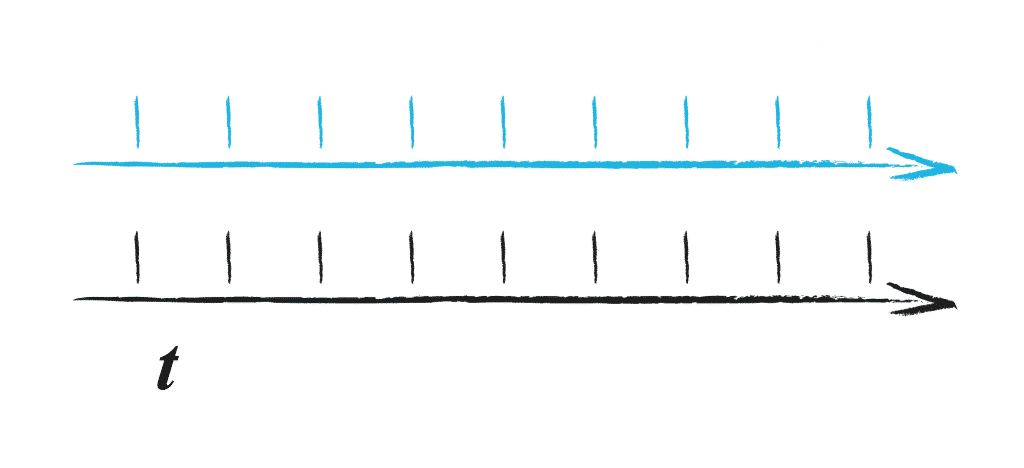
This way, devices can be compared more easily to each other, or it’s aggregated together. How the interpolation is done depends on the type of data we are looking at and the kind of analysis we want to perform on the data. An illustrative example of two use cases with the same data.
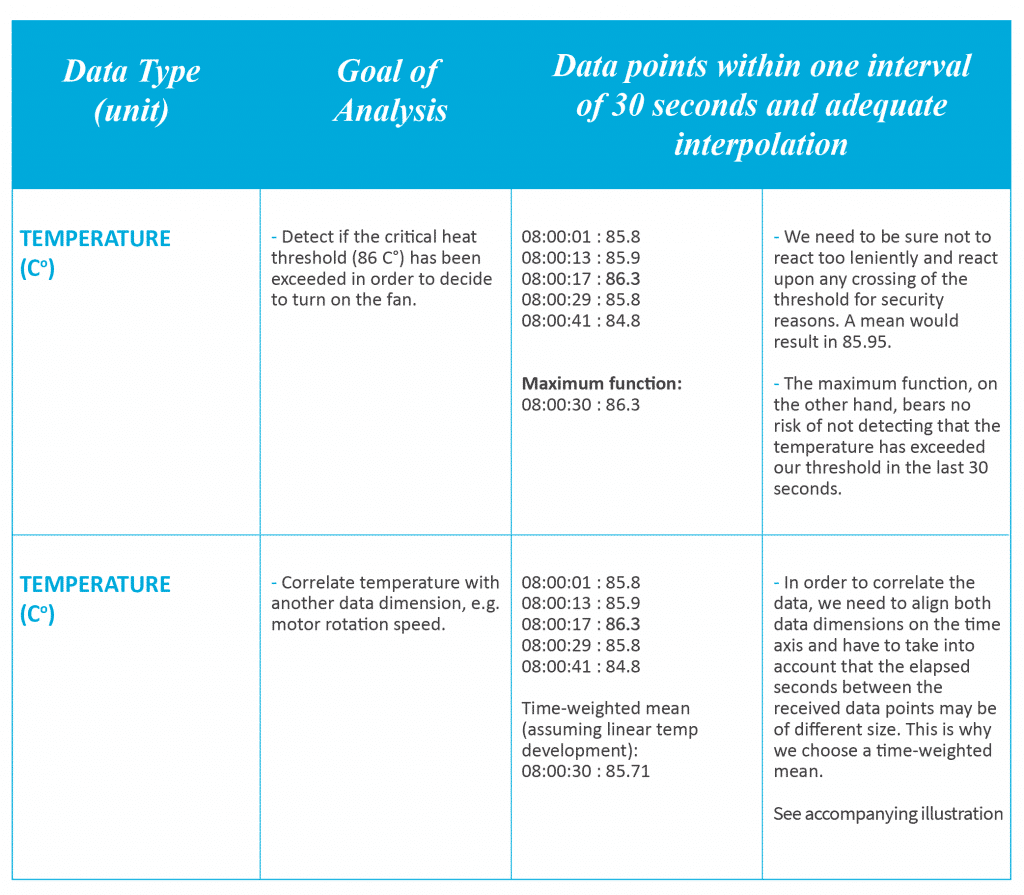
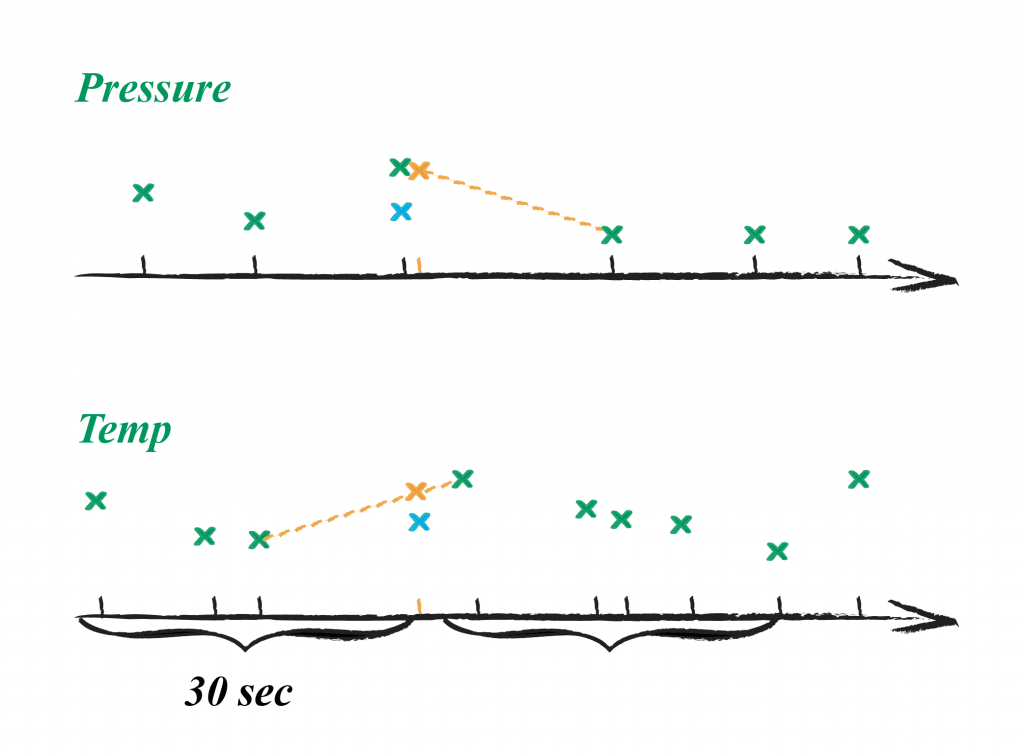
As exemplified in the table, if we have a use case where we have to correlate with high precision with another data dimension (e.g. oil pressure with motor temperature) on historical or near-live data, we can wait for the data point of the next 30-second interval and calculate a time-weighted mean as this represents the real-world situation more accurately. Another important point is that we apply the same paradigm to both data dimensions which we want to compare or correlate afterward. In the above graphic, we see the data points in green, the calculated mean of the interval in light blue and the calculated time-weighted mean at the requested time point in orange.
The mentioned examples are simple use cases. Often times employing complex aggregation methods are necessary as there are many different devices of a certain type involved for a use case for which specialised interpolation methods are available.
The important message here is that we need to think about what it is we want to do with the data and what use cases the data is used for before we know how to handle and transform the raw data adequately.
Where do we store and serve our data for use by other teams, business intelligence and data scientists?
One question is how to handle the data on a mathematical basis, but another issue is where and how we should push, transform, serve and archive the data and its derived data products.
Particularly for large organisations, hosting large data quantities that serve running applications is a central issue. Traditionally, the company IT needed to make sure all projects and apps had an adequate amount of storage space on the on-prem infrastructure and at the same time guarantee that the queries ran smoothly and quickly. Those two aspects have often led to challenges, particularly for data-hungry endeavours, that have become more of a norm than an exception. Cloud solutions arrived with the promise of tackling these two issues at once: Instant availability and scalable running environments over the whole globe.
Furthermore, companies without data strategy tend to create many copies of the same data as different entities need the same data in different aggregation forms. For example, data scientists and BI (business intelligence) specialists have different requirements.
On the one hand, most traditional on-prem technologies have adapted and can be licensed on cloud services in order to offer an easy transition (Oracle RDBMS solutions, Hadoop, MongoDB). On the other hand, new solutions have emerged, blending together certain aspects of storage and computing as well as data capabilities. One such example is Snowflake, a cloud-native data storage and computation solution with a focus on accessibility. This means that although the solution itself uses a tabular storage scheme, the input may be ingested in JSON, XML or other specific formats, which may also be queried. As Snowflake includes computational clusters, we may choose to perform data transformation used for serving different clients within the solution itself. We can share certain snapshots of the data with business intelligence for creating reports; we may give access to a data scientist who uses the Python library for exploratory analyses directly on the data or we may use different connectors for ETL processing within the Snowflake instance or serve data to further data processing outside of Snowflake
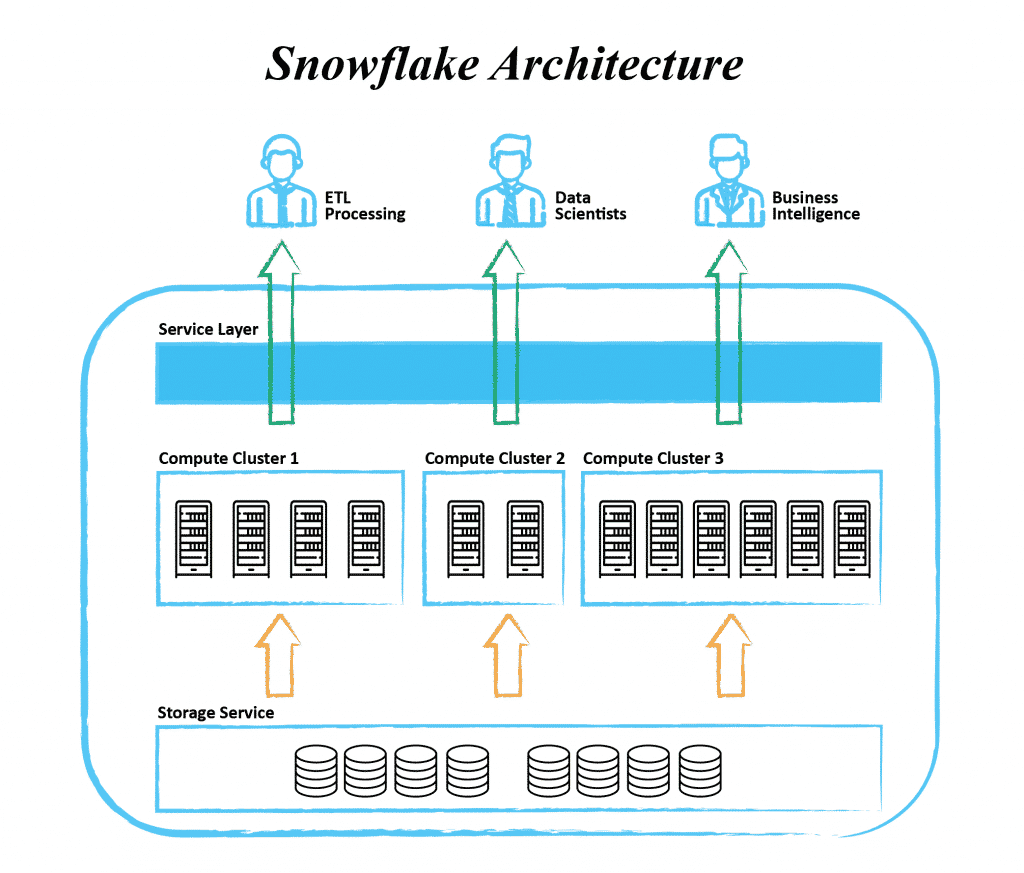
The image shows a schematic architecture of how the Snowflake solution is built. Similar to current data warehouse and data lake solutions, how the data is organised internally is still a matter of who we need to serve what data to and in what aggregation form, meaning we still need to rack our brains on how to best organise and transform our data.
Connecting the dots
(Christian Glück – Enterprise Agility)
As you can see, there is a lot to technically consider when starting an IoT journey with the goal of making more use of the available data. Besides how to get the data, of new or old devices, into the cloud, considerations about the proper signal (pre-)processing needs to be made before the data is presented and put to use.
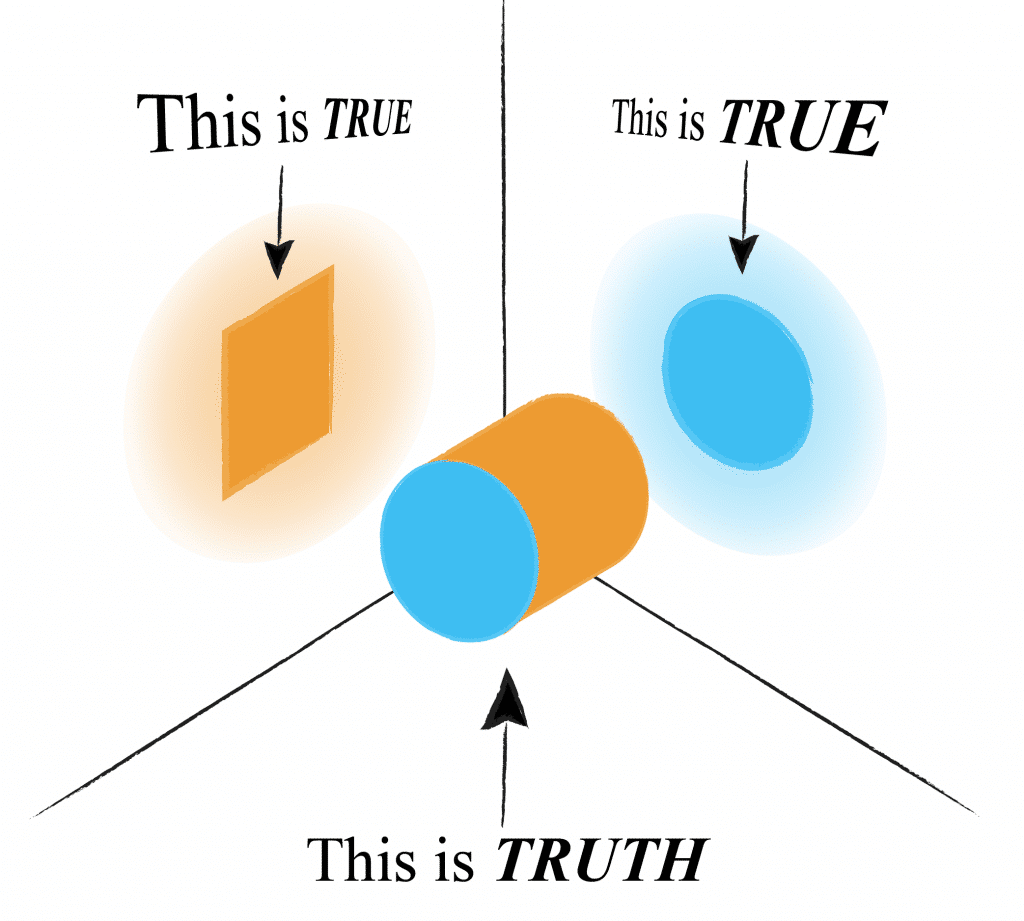
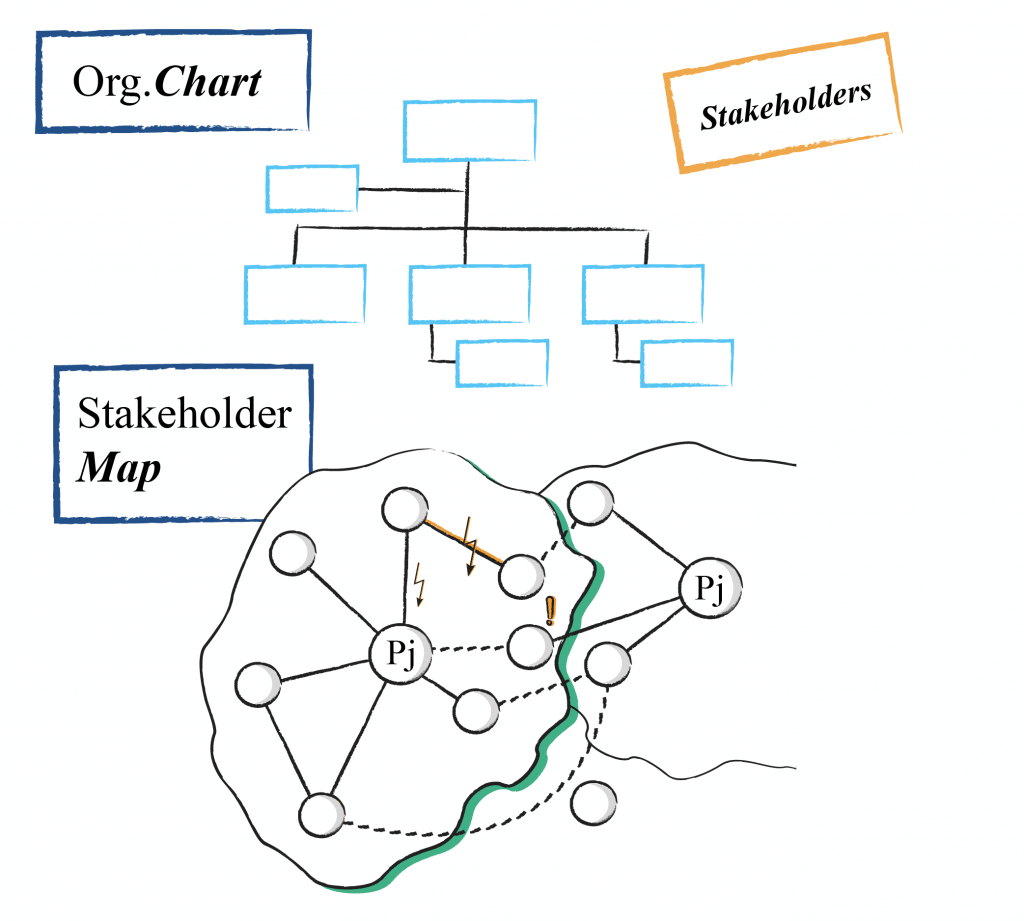
But as a basis, the alignment between the different stakeholders always needs to be taken care of. At ERNI we have seen a lot of initiatives like this fail, as not all dots were properly connected or not everybody was aware of the present dots. Misalignment and misunderstanding often lead to out-of-sync solutions and, over the product’s lifecycle, to really cost-intensive and hard to maintain services. Therefore, it’s important to get all stakeholders aligned right from the start and share the mutual vision. We need to understand that everybody interprets the truth from one’s own point of view (see picture below). So, it’s really necessary to speak about everyone’s perspective to get as close to the truth as possible.
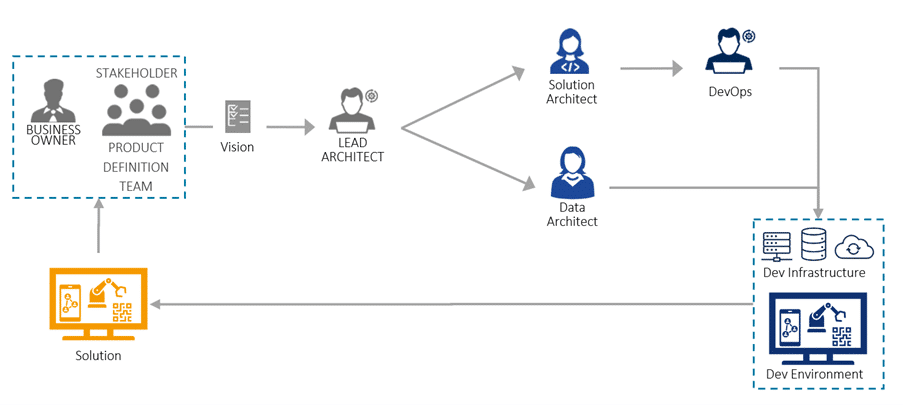
In the above context, business representatives need to share and define the product vision in order for the architects to shape the right solution, the architects need to present their architectural runway in order for the data scientists to define the right strategy, devops engineers need to understand the overall strategy to develop a robust CI/CD pipeline and product and in return, business needs to understand again how to use and market the build solution.
And it is not enough to lay this foundation at the beginning and then see it slowly dissolve; it needs to be taken care of over the whole lifetime. Short feedback cycles are needed between all players, to keep them as closely aligned as needed.
So, whenever we at ERNI start a product journey together with our customers, we take all of the above into consideration so the product will be a market success over the whole product lifecycle!
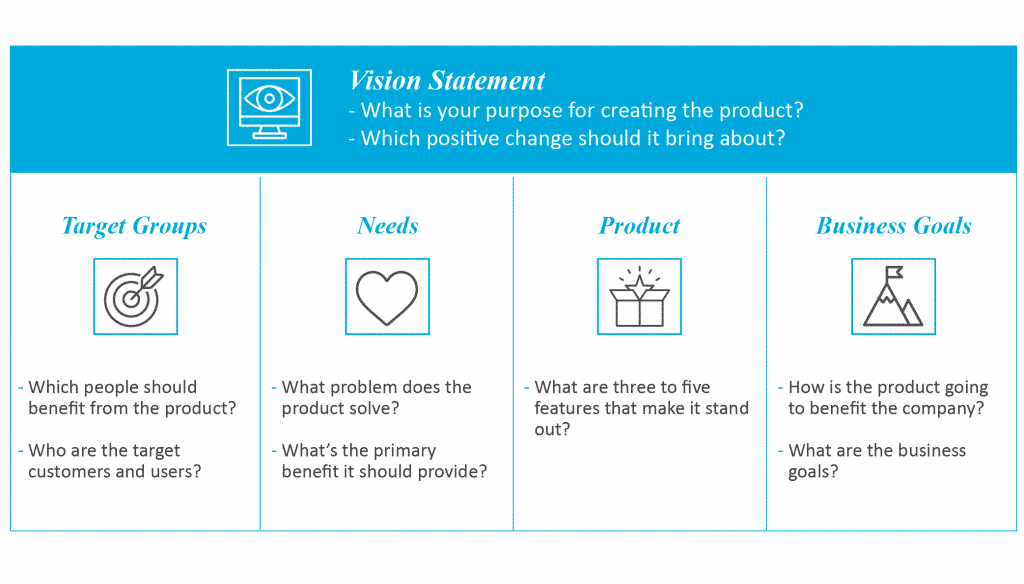
We start by creating a product vision, helping to define what business goals we want to achieve and how to achieve them, including defining the product’s stand-out features.
A proper stakeholder map and stakeholder analysis is done to be sure all parties have been identified and get their input at the right time. We take care that the main requirements have been created and everybody understands the system context. Once all of this is clear, aligned and properly documented, we start creating the collaboration model, which could look like the one below.
We take care that all actors are properly integrated, the information, as well as development flow, is clear and the feedback cycles are defined.
Setting it up like this, we are confident that the product will be a market success!