
Over the past few months, generative artificial intelligence models have taken the world by surprise. They’re creating mind-blowing outputs like never before, and people can’t get enough of it. These models have demonstrated their ability to create hyper-realistic images, original music across various genres, coherent texts and synthetic videos, captivating the imagination of both the technology community and the general public.
The advancements in these models have engendered an unprecedented enthusiasm, with promises of a new era of AI-powered creativity. However, amidst this thrilling progress, it is imperative to acknowledge and address the ethical and societal inquiries arising from their use. Responsible utilisation of generative AI is paramount to ensuring its ethical and beneficial impact on society, while simultaneously mitigating potential challenges related to misinformation and manipulation.
Large Language Models: Our vision
Today we are going to explore Large Language Models, a type of generative AI system that comprehends and generates human language in a natural manner. They act as advanced virtual assistants capable of processing written or spoken text, translating, answering questions and creating creative content such as poetry or music, or even generating code in many of the current programming languages. It could be said that LLMs are Swiss Army Knives when it comes to text generation of any kind. They learn from vast amounts of text data, enabling them to improve their precision and understanding over time.
LLMs are actively being implemented in various industries and applications such as content generation, chatbots, customer support systems, code completion, language translation and more. Companies integrate LLMs into their products and services by leveraging their powerful language generation capabilities. These models can be fine-tuned on domain-specific data to improve their performance and relevance to particular tasks
In the future, LLMs are expected to play an increasingly pivotal role in revolutionising various fields. As their capabilities continue to advance, they will likely find applications in areas such as medical diagnosis, legal document analysis, personalised education and creative writing assistance. Moreover, LLMs could facilitate seamless multilingual communication, breaking down language barriers in global interactions. The integration of LLMs with augmented reality and virtual reality technologies may lead to more immersive and interactive experiences where AI-powered virtual assistants could interact with users in a lifelike manner. Furthermore, ethical considerations and responsible AI practices will become more crucial as LLMs become deeply embedded in society, necessitating the development of robust frameworks to ensure transparency and accountability. Overall, the future of LLMs is brimming with possibilities, promising to reshape industries and enhance human-machine interactions in unprecedented ways.
Now that we know what an LLM is and what is it intended for, let’s go deeper into the different options in the market, how to configure them, and the limitations they currently have. Understanding these aspects and knowing the best practices in prompting will enable us to harness the full potential of LLMs and grasp their significance in various domains.
LLMs: The top 3
The world’s leading technology companies are actively engaged in a race to develop the most accurate and widely adopted LLM models. In the following table, we will explore the three most renowned models and some of their key features:

These prominent models showcase the cutting-edge advancements in language processing and are being implemented in numerous applications, revolutionising how we interact with AI-powered technologies. The competition among tech giants to refine these models further highlights the significance of LLMs in shaping the future of artificial intelligence and human-machine interactions.
Behaviour and limitations
Each LLM comes with several configuration options that can be adjusted to control the output generated. These options include:
- Temperature: This determines the randomness of the generated text. Higher values (e.g., 0.8) result in more diverse outputs, while lower values (e.g., 0.2) produce more focused and deterministic outputs.
- Max tokens: This option limits the length of the generated text. By setting an appropriate value, one can control the response length to match the desired requirements.
- Frequency penalty: This penalises the repetition of similar phrases in the generated text, encouraging diversity in the output.
- Presence penalty: This penalty discourages the model from mentioning certain words or phrases, enabling more controlled responses.
In addition to these customisations, we can train our own model through a fine-tuning technique, providing a substantial volume of prompts and expected responses. We define fine-tuning as the process in which we take a pre-trained language model and further train it on specific data related to a particular task. It helps the model adapt and become more accurate in performing a specific job, like answering questions or generating text. However, it requires a considerable amount of carefully selected data and expertise to avoid potential issues and achieve optimal results. This allows our model to acquire new information to work with. However, currently the community does not highly recommend this approach due to potential challenges and risks associated with fine-tuning.
If we want an LLM to work with our personal information, we can use Natural Language Processing (NLP) techniques to establish connections between our prompt and our data. By doing so, we can subsequently utilise our LLM to obtain relevant information “without prior knowledge”, yielding highly accurate responses while preserving the privacy of our data. Moreover, this approach allows us to trace the specific source of our data from where the information was obtained. In the following graph, we can see how this technique would work.
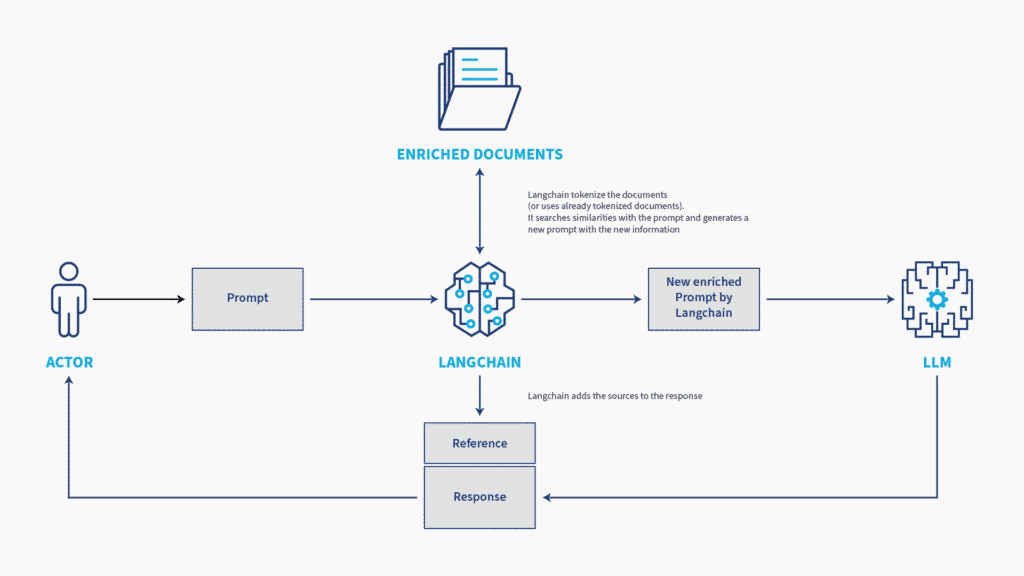
As powerful as LLMs are, there are some concerns that we have to take into account, one of the most important being that of data security and privacy. Since LLMs are trained on vast amounts of data, they can inadvertently learn and reproduce sensitive or private information. Organisations need to be cautious when deploying LLMs and take necessary measures to prevent unintended disclosure of confidential or personal information.
The rise of LLMs brings with it ethical concerns and potential biases that warrant careful consideration. As these models become increasingly prevalent in various applications, we must address the ethical implications they pose. LLMs learn from datasets, including internet content, which can inadvertently perpetuate existing biases present in the data. If not properly monitored and corrected, this could lead to discriminatory outputs, reinforcing societal inequalities. Additionally, the opacity of these models raises questions about accountability and transparency, as it becomes challenging to trace the decision-making process. Ensuring the responsible and fair use of LLMs is essential to mitigating bias and upholding ethical standards in AI applications. As we continue to harness the power of LLMs, it is crucial to implement robust safeguards and ethical guidelines to make AI a force for positive change while minimising harmful impacts.
Another issue to consider is that LLMs operate within predefined token limits. The total number of tokens (In natural language processing (NLP), a token refers to a single unit of text, which could be a word, character, or subword, used for language analysis and processing tasks) in an input prompt and the model’s context affect the output length. Exceeding these limits can result in truncation or incomplete responses. Token constraints require careful management, and long prompts or extensive conversations may need to be shortened or split to ensure accurate and coherent output. Currently, the models with the most context tokens typically operate around 32k tokens.
Prompting: Get the most out of LLMs
Now that we know what LLMs are, their configuration and limitations, let’s get down to the useful stuff: learning how to get the most out of the technology.
Prompting is a crucial concept in the realm of language models and natural language processing. It refers to providing specific instructions or input to guide the behaviour of the model during the generation process. By carefully crafting prompts, we can control the output and tailor the responses to our desired outcomes. This technique is essential because it allows us to elicit more accurate and relevant information from the language model, ensuring that it aligns with our specific needs, and enhances its practical applications across various domains, from creative writing to customer support and beyond. Let’s see how it works with some examples:
- Be Clear and Specific:
Poor Prompt: “Tell me about cars.”
Improved Prompt: “Provide a brief overview of the history of electric cars and their environmental benefits.”
- Provide Context:
Poor Prompt: “Who was the first president of the United States?”
Improved Prompt: “In the late 18th century, a prominent figure played a pivotal role in leading the newly formed United States. Can you tell me who this person was?”
- Ask Open-ended Questions:
Poor Prompt: “Is climate change real?”
Improved Prompt: “Explain the scientific consensus on climate change and its potential impacts on the environment and society.”
- Set a Length Limit:
Poor Prompt: “Describe the process of photosynthesis.”
Improved Prompt: “Explain the process of photosynthesis in about 100 words.”
- Use a role for the model:
Poor Prompt: “What do you think about smartphones?”
Improved Prompt: “As a tech reviewer, please provide an analysis of the latest smartphone trends.”
Conclusion
In conclusion, Large Language Models (LLMs) have emerged as a transformative force in natural language processing, reshaping the way industries interact with and utilise text data. By incorporating LLMs into various domains, businesses have witnessed enhanced customer interactions, improved content generation and streamlined data analysis. The ability to customise LLMs to cater to specific tasks has been a game changer, enabling tailored solutions for different industries. However, it is essential to acknowledge the current limitations. As LLM technology continues to evolve, addressing these challenges will be critical to unlocking their full potential and ensuring ethical and unbiased deployments. With ongoing research and development, the future of LLMs promises to usher in even more profound advancements, opening up new possibilities for seamless human-machine language interactions. At ERNI, we have already started to witness the advantageous impact of generative AI, which has opened up an array of innovative possibilities and use cases for our organisation. Our endeavours range from implementing internally tailored and secure LLMs within corporate environments to crafting specialised applications catering to the unique needs of developers and diverse industries. Through these diverse approaches, we are continuously leveraging the power of generative AI to foster efficiency, creativity and enhanced solutions for our clients and stakeholders.
References
Eloundou, T., Manning, S., Mishkin, P., & Rock, D. (2023). “GPTs are GPTs: An Early Look at the Labor Market Impact Potential of Large Language Models.”
“Prompt Engineering Roadmap.” Retrieved from https://roadmap.sh/prompt-engineering
“Your Guide to Communicating with Artificial Intelligence” Retrieved from https://learnprompting.org/
“LLM Models Comparison: GPT-4, Bard, LLaMA, Flan-UL2, BLOOM” retrieved from https://deepchecks.com/llm-models-comparison/#post-item-8
“GPT-3: Language Models are Few-Shot Learners” retrieved from https://github.com/openai/gpt-3